Technology
Atlantic exposes 21 million songs used to train AI models

Artists and labels now have a way to look for their own music inside four huge training datasets, a shift that turns the AI copyright fight from abstraction into something far more personal. The Atlantic’s Alex Reisner made the collections fully searchable as part of the outlet’s AI Watchdog project, exposing more than 21 million recordings that have circulated among artificial intelligence developers.
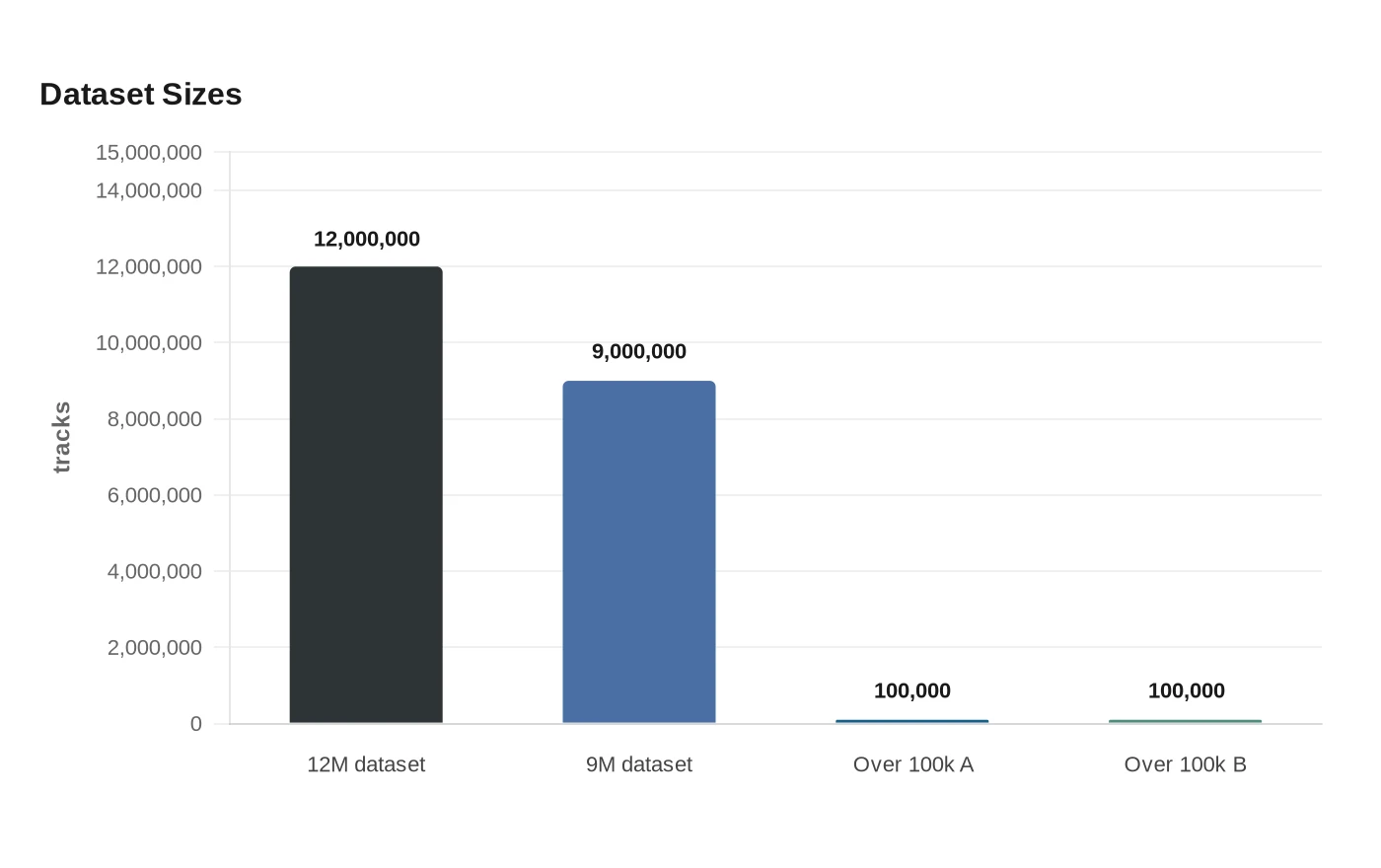
The scale is staggering. Two of the datasets contain about 12 million and 9 million tracks, while the other two each hold more than 100,000 recordings. One report described the 12-million-track collection as roughly 91 years of music if played back-to-back. The database includes songs by Taylor Swift, Bad Bunny, Nirvana, Billie Eilish, Pearl Jam and The Beatles, along with jazz artists and classical composers.

The largest collection is LAION-DISCO-12M, released in November 2024 by LAION, a German nonprofit that compiles open datasets for AI research. LAION says the collection was released for research purposes and warns against commercial use. The dataset contains links to public YouTube tracks and metadata, not audio files, underscoring how training material can be assembled from pieces scattered across the open web rather than from a single licensed archive.
Another key collection is the Free Music Archive, published in 2017 for music-information-retrieval research and built from recordings released under permissive Creative Commons licenses. The Atlantic reported that Google and Stability AI used tracks from that archive. The remaining two datasets are smaller, but still represent significant stores of training material.

The new search tool changes the argument over accountability. The Atlantic’s own explorer cautions that finding a song in a dataset is not definitive proof that it was used in training, because companies may leave works out and may combine multiple datasets. Even so, the visibility matters. For artists, publishers and labels, the database offers concrete evidence to test claims that had previously depended on inference, sealed records or disputed company disclosures.
That evidence arrives as the legal battle around AI music generation is intensifying. Music companies began suing Suno and Udio in June 2024, when the RIAA filed on behalf of Universal Music Group, Sony Music Entertainment and Warner Music Group over what it called mass infringement. Music Business Worldwide reported that Suno and Udio are now facing at least 12 lawsuits, while all four datasets have each been downloaded several thousand times.
For creators, the significance is not just that songs may have been copied into training pools. It is that the pools are no longer invisible. Once a musician can point to a searchable dataset and find a track, the debate moves from speculation to a testable claim, and from policy talk to a question of legal remedy.