Technology
OpenAI’s loop pushes agentic AI toward nonstop automation
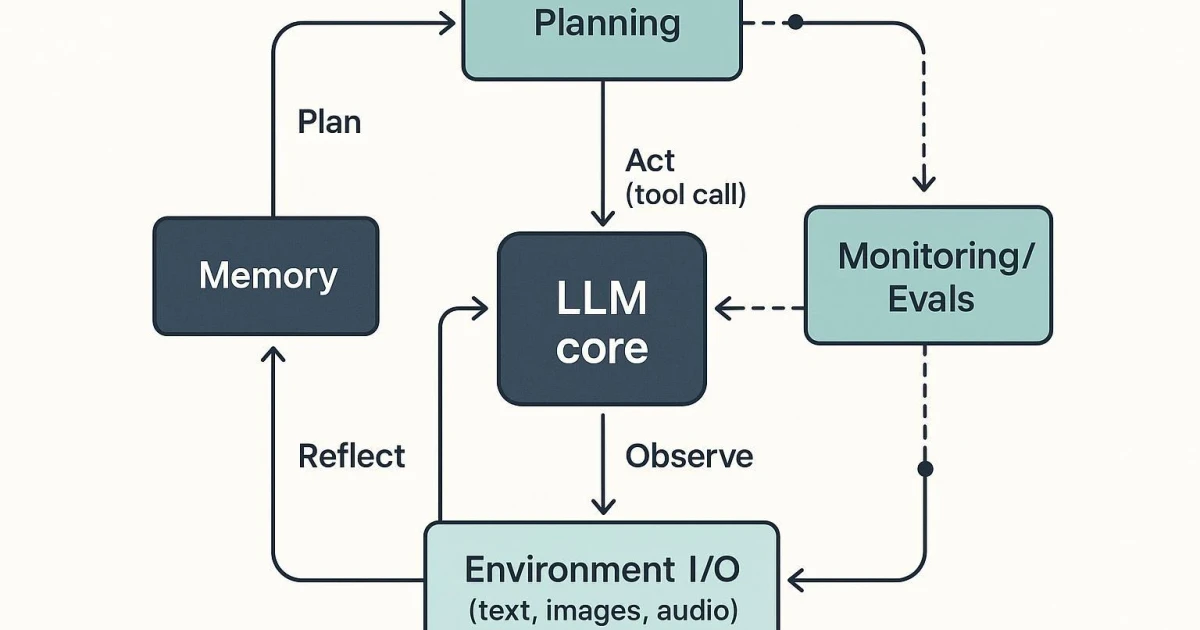
OpenAI’s push into looping agents marks a sharp break from the familiar chatbot model. Instead of waiting for a fresh prompt, a swarm of agents can keep gathering context, choosing actions, observing results and repeating the cycle in the background until a task is done or a stop condition kicks in. That shift makes agentic AI more useful, but it also turns governance into the central problem, because the system can keep acting after the human has stopped watching.
What a loop changes
MIT Sloan describes agentic AI as semi- or fully autonomous systems that can perceive, reason and act on their own, and the loop is the operating rhythm that makes that autonomy practical. In a simple chat interaction, the model answers and stops. In an agent loop, each step becomes a new decision point, which means the machine can keep working without another human prompt.
That distinction matters because continuous action changes the unit of risk. A chatbot can produce a bad answer; a looping agent can chain together bad answers, bad decisions and bad actions across multiple steps. In other words, the failure mode is no longer a single mistaken response, but a process that keeps moving.
Why nonstop automation gets expensive fast
The most immediate issue is cost. Every pass through the loop consumes tokens, compute and time, so a system that runs for many iterations can quickly become expensive even when each step looks small in isolation. If the work is open-ended, a simple task can become a long tail of repeated reasoning and repeated tool calls.
State is the second problem. The more times an agent loops, the more it must carry forward what happened before, which raises the chance of confusion, drift and compounding error. When state becomes messy, a model may revisit the same dead end, misread prior context or act on stale assumptions, all of which make the system harder to debug and harder to trust.
There is also the danger of runaway behavior. If stopping conditions are poorly designed, the loop can keep firing when it should have stopped, or it can continue pursuing a flawed objective long after a human would have intervened. That is what makes loopy AI different from ordinary automation: the system is not just executing a script, it is repeatedly deciding whether the script should continue.
The governance problem is bigger than the model
OpenAI’s governance paper makes the core point plainly: agentic AI systems can create risks of harm and require agreed baseline responsibilities and safety best practices across the full life cycle. That language is important because it shifts the conversation away from model quality alone. The real question is who is responsible for permissions, monitoring, escalation, shutdown and post-incident review when the agent is always on.
This is where oversight and liability start to blur. If a system can keep acting without fresh approval, the organization must define who can authorize actions, who can audit them and who absorbs the damage when something goes wrong. In practice, the more autonomous the agent, the more likely it is that a failure will expose gaps in internal controls, vendor management and legal accountability.
Security is part of that same picture. A looping agent that can access tools, data or downstream systems needs tight boundaries, because persistence creates more opportunities for misuse, misfire or unintended side effects. The governance challenge is not just stopping a bad answer; it is preventing a long-running system from turning a small mistake into a larger operational incident.
Why builders are reaching for simpler patterns

Anthropic’s guidance, published on December 19, 2024, points in a telling direction: the most successful agent implementations tend to use simple, composable patterns rather than complex frameworks. That is a notable contrast to the instinct to pile on abstraction. Simpler systems are usually easier to test, easier to monitor and easier to stop, which matters when the software is allowed to keep working on its own.
OpenAI’s own tooling story shows how quickly the market is moving. The company’s experimental Swarm framework has been replaced by the OpenAI Agents SDK, which it describes as a production-ready evolution. The shift from experiment to production signals that the industry is trying to turn agent ideas into deployable infrastructure, but it also shows that the field is still unsettled enough that the underlying architecture is changing fast.
The strategic lesson is straightforward: in agentic systems, elegance is not the same as control. A sprawling framework may look powerful, but if it is hard to inspect or bound, it becomes harder to govern. Simpler patterns may look less ambitious, yet they often produce the operational clarity that nonstop automation needs.
Where the market is already using agents
MIT Sloan Management Review says deployment is increasing across software engineering and customer service, two areas where repetitive work and clear output targets make agents attractive. In software engineering, an agent can draft code, test changes and iterate. In customer service, it can triage, respond and route issues without waiting for every instruction from a human.
Those are exactly the kinds of environments that make the risk tradeoff visible. The upside is speed and scale. The downside is that transparency about technical components, actual uses and safety remains limited, so organizations may be rolling out systems they do not fully understand. That gap between deployment and visibility is where governance failures usually begin.
MIT Sloan’s view that the age of agentic AI has arrived captures the macro trend. The market is moving from one-off demonstrations to embedded operations, and once agents are inside core workflows, their errors become business problems rather than lab curiosities. That is why the loop matters so much: it is the mechanism that turns a model into a persistent operator.
What companies need to manage now
Any organization building around agent loops needs a tighter operating model than the one used for ordinary chatbots. The essentials are clear:
• Define explicit stopping conditions, not vague ones. • Put hard limits on spend, iterations and tool access. • Require human review at the points where actions can create real-world impact. • Log every step so decisions can be reconstructed later. • Separate experimentation from production, and keep production systems simple enough to audit.
These controls are not optional decoration. They are what stand between a useful autonomous workflow and a machine that keeps working after it should have been switched off. The next wave of AI will not be judged only by how well it reasons, but by whether it can be trusted to stop.
Sources
- [1]techcrunch.com
- [2]openai.com
- [3]anthropic.com
- [4]openai.github.io
- [5]mitsloan.mit.edu
- [6]sloanreview.mit.edu
- [7]code.claude.com